Why this happens, and what it means for you
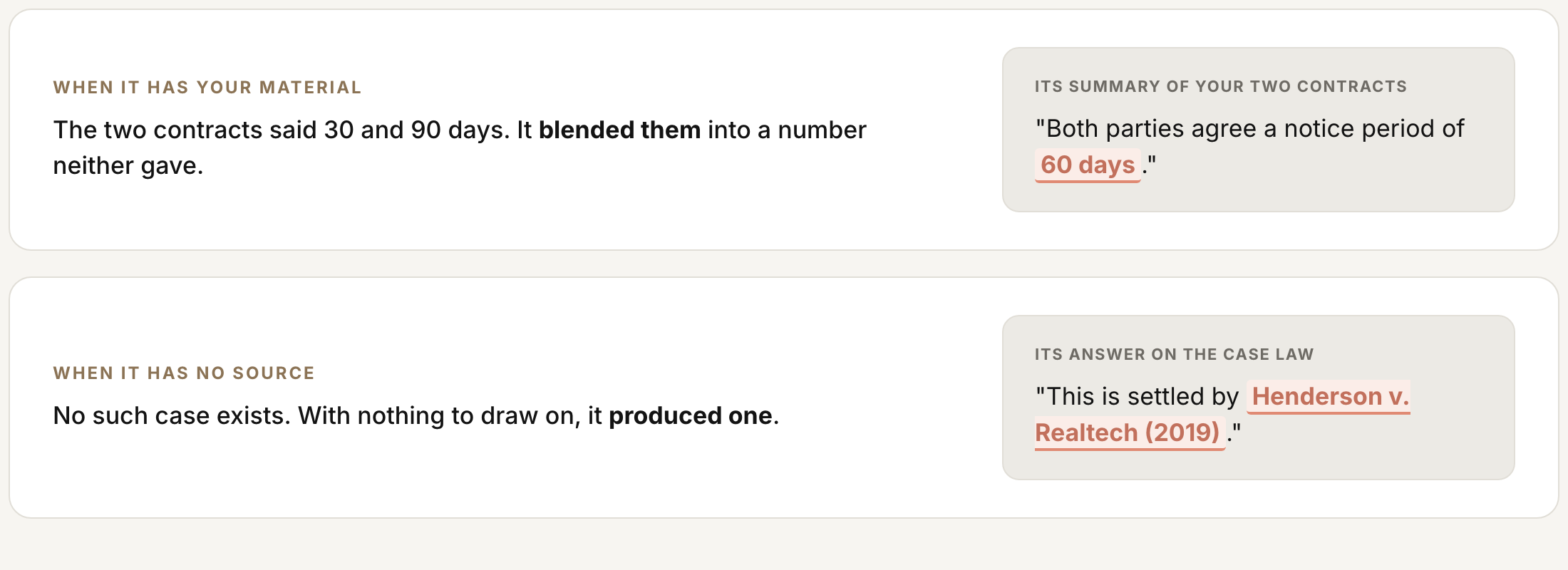
When AI "hallucinates" it sounds completely sure of itself while being wrong. It happens two ways: it misreads or muddles material you gave it, or it invents from nothing when its information is thin.
It is built into how these models work: they predict plausible text, and guessing is rewarded in training [1]. Which leads to the one split that matters most: working from sources beats working from memory. The bars below show how often each invents content, where lower is better.
![How often AI invents content, compared. Grounded and reliable, from material you give it: around 3 percent of cases, and improving [4]. From memory and unreliable, recalling facts on its own: around 33 percent, with OpenAI's o3 inventing answers on a third of person-facts questions [3].](ten-habits-fig-grounded-recall.png)
Adopting the 10 habits is mostly about pushing your work to that grounded side. One last thing, because it powers several of them: fabrications are unstable. Ask for an invented reference twice and the details drift, where real knowledge stays put [2].